What is a UUID?
A UUID (Universally Unique Identifier) is a 128-bit value used to identify resources without a central authority. Defined by RFC 9562, UUIDs enable distributed systems to generate identifiers independently with virtually zero risk of collision. The standard format is 32 hexadecimal digits in five groups:
550e8400-e29b-41d4-a716-446655440000.
Every backend service, every database table, every message queue needs identifiers. A good UUID generator gives you those identifiers instantly, without coordinating with a central server and without worrying about duplicates. But UUIDs are no longer the only option. Newer formats like ULID, NanoID, and KSUID solve problems that UUIDs were never designed to handle.
This guide covers the major UUID versions, explains when each one makes sense, compares them to modern alternatives, and shows you how to generate any of them in seconds.
Table of contents
- UUID versions explained
- Which UUID version should you use?
- Beyond UUIDs: ULID, NanoID, and KSUID
- How to generate UUIDs in code
- UUID collision probability: the actual math
- UUID as a database primary key
- UUID generator: SelfDevKit
- Frequently asked questions
UUID versions explained
RFC 9562 (published May 2024, replacing RFC 4122) defines eight UUID versions. Three matter for everyday development: v1, v4, and v7.
UUID v1: timestamp + MAC address
UUID v1 encodes the current timestamp and the generating machine's MAC address into the identifier. This means v1 UUIDs are unique across machines and sortable by creation time.
The problem? They leak your hardware address. Anyone who reads a v1 UUID can extract the MAC address of the machine that generated it. For internal tooling this might be acceptable. For public-facing APIs, it is a privacy risk.
f47ac10b-58cc-11e4-8c21-0800200c9a66
^^^^^^^^^^^^
MAC address embedded here
UUID v4: purely random
UUID v4 is the most widely used version. It fills 122 of 128 bits with cryptographically random data, leaving 6 bits for version and variant markers.
550e8400-e29b-41d4-a716-446655440000
^^^^ version nibble = 4
No timestamp, no MAC address, no leaked metadata. Just randomness. This makes v4 the default choice when you need a unique identifier and nothing else.
UUID v7: timestamp + random (the new default)
UUID v7 is the newest practical version, introduced in RFC 9562. It combines a Unix timestamp in milliseconds (48 bits) with random data (74 bits). The result is an identifier that is both unique and chronologically sortable.
018f3c2b-7c5a-7b91-9c8e-2f1c4d3a9b12
^^^^^^^^ ^^^^ millisecond timestamp prefix
Why does sortability matter? Because B-tree indexes in databases perform dramatically better when inserts arrive in roughly sorted order. Random v4 UUIDs scatter inserts across the index, causing page splits and fragmentation. v7 UUIDs insert at the end, keeping the index tight.
The RFC itself recommends v7 over v1 and v6 for new implementations.
UUID v3 and v5: namespace-based (niche use)
UUID v3 (MD5) and v5 (SHA-1) generate deterministic IDs by hashing a namespace and a name together. Given the same inputs, they always produce the same UUID. This is useful when you need reproducible identifiers, for example, generating a consistent UUID from a URL or DNS name. In practice, most developers reach for v4 or v7 instead. If you do need deterministic IDs, prefer v5 over v3 since SHA-1 is a stronger hash than MD5.
Which UUID version should you use?
For most new projects, UUID v7 is the right answer. Here is a quick decision matrix:
| Scenario | Recommended version | Why |
|---|---|---|
| Database primary key | v7 | Sortable, excellent index performance |
| API resource identifier | v4 or v7 | No metadata leakage, widely supported |
| Distributed event ordering | v7 | Timestamp prefix enables natural ordering |
| Legacy system compatibility | v4 | Universally supported across all libraries |
| Tracing and correlation IDs | v7 | Timestamp helps when debugging timelines |
| Client-side generation in browsers | v4 | crypto.randomUUID() natively generates v4 |
If you are starting fresh and your language or library supports v7, use it. You get everything v4 offers plus chronological ordering at zero extra cost.
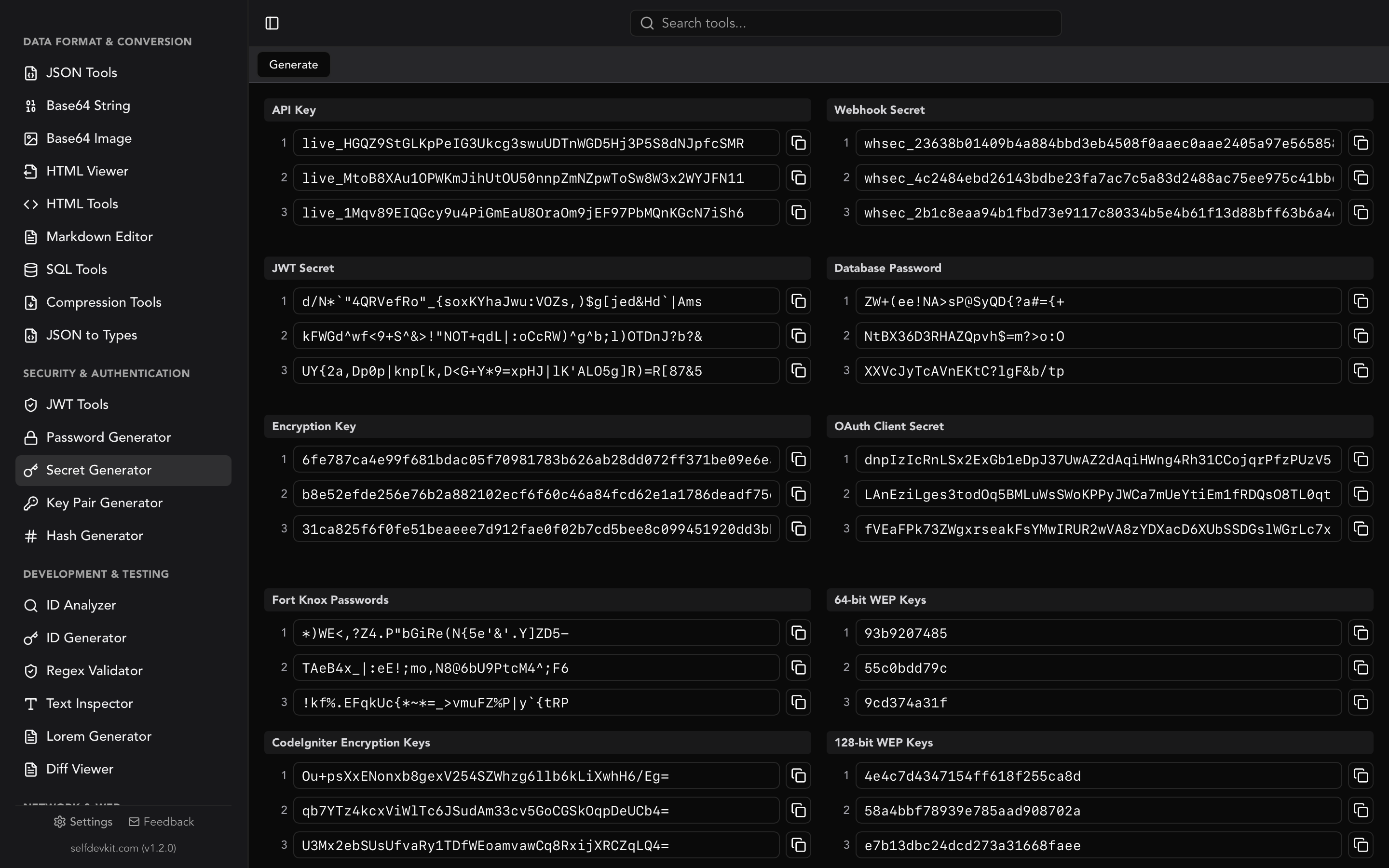
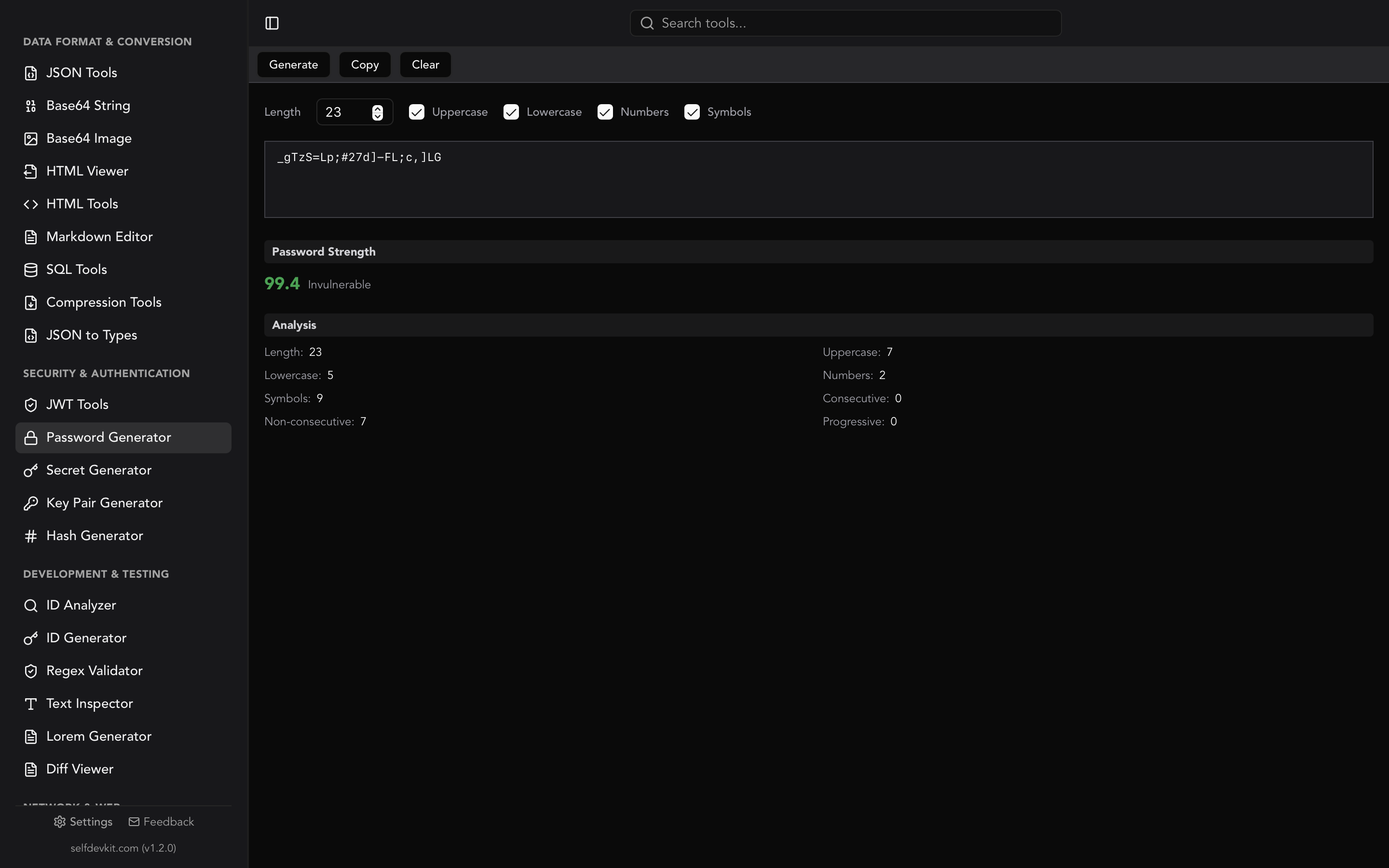
If you need cryptographic secrets rather than identifiers, a UUID is the wrong tool. Use a dedicated secret generator or password generator instead.
Beyond UUIDs: ULID, NanoID, and KSUID
UUIDs are not the only game in town. Several alternative ID formats have emerged to address specific shortcomings.
ULID (Universally Unique Lexicographically Sortable Identifier)
A ULID is a 128-bit identifier encoded as 26 Crockford Base32 characters. The first 10 characters encode a 48-bit Unix timestamp in milliseconds; the remaining 16 encode 80 bits of randomness.
01ARZ3NDEKTSV4RRFFQ69G5FAV
^^^^^^^^^^ ^^^^^^^^^^^^^^^^
timestamp randomness
Key advantages over UUID:
- Lexicographically sortable as plain strings (no special comparators needed)
- URL-safe with no hyphens or special characters
- Case-insensitive, reducing human transcription errors
- Monotonic ordering within the same millisecond (some implementations)
ULIDs are excellent for logging systems, event streams, and anywhere you want compact, sortable IDs without the hyphenated UUID format.
NanoID
NanoID generates URL-friendly identifiers using a cryptographic random number generator. The default output is 21 characters from a 64-character alphabet (A-Za-z0-9_-).
V1StGXR8_Z5jdHi6B-myT
At 21 characters, NanoID is roughly 40% shorter than a UUID while providing comparable collision resistance. The length is configurable; shorter IDs trade collision resistance for compactness.
NanoID fits well as session tokens, short URL slugs, and client-side identifiers where brevity matters.
KSUID (K-Sortable Unique Identifier)
KSUID uses a 160-bit structure: 32 bits for a timestamp (second precision, offset from a custom epoch of May 13, 2014) and 128 bits of random payload. The result is a 27-character Base62 string.
2G1jMfDNToSvCwiEHm7bJBfOI3c
The extra 128 bits of randomness (compared to ULID's 80 or UUID v7's 74) make KSUIDs especially resistant to collisions in high-throughput systems. They work well for event-driven architectures, Kafka message keys, and audit logs where you need both sortability and extremely high collision resistance.
Comparison table
| Format | Length | Sortable | Timestamp | Bits of randomness | Standard |
|---|---|---|---|---|---|
| UUID v4 | 36 chars | No | No | 122 | RFC 9562 |
| UUID v7 | 36 chars | Yes | ms precision | 74 | RFC 9562 |
| ULID | 26 chars | Yes | ms precision | 80 | Community spec |
| NanoID | 21 chars (default) | No | No | ~126 (at 21 chars) | Community spec |
| KSUID | 27 chars | Yes | second precision | 128 | Community spec |
SelfDevKit's ID Generator supports all five formats. Generate any of them instantly, in batches, and copy the results with one click.
How to generate UUIDs in code
Most languages have built-in or standard library support for UUID generation. Here are the most common approaches.
JavaScript / TypeScript
Modern browsers and Node.js (v19+) support crypto.randomUUID() natively for v4:
// UUID v4 - built-in, no dependencies
const id = crypto.randomUUID();
// "3b241101-e2bb-4d5a-8c8b-0e3e8d907f72"
For v7 or other formats, use the uuid package:
import { v7 as uuidv7 } from 'uuid';
const id = uuidv7();
// "018f3c2b-7c5a-7000-9c8e-2f1c4d3a9b12"
Python
Python's standard library handles v1 and v4. For v7, use the uuid6 package:
import uuid
# v4 - cryptographically random
print(uuid.uuid4())
# 7c9e6679-7425-40de-944b-e07fc1f90ae7
# v1 - timestamp + MAC address
print(uuid.uuid1())
# f47ac10b-58cc-11e4-8c21-0800200c9a66
For v7 in Python, uuid6 provides a drop-in extension:
import uuid6
# v7 - timestamp-sortable
print(uuid6.uuid7())
# 018f3c2b-7c5a-7b91-9c8e-2f1c4d3a9b12
Note that Python 3.x's uuid.uuid4() uses os.urandom() under the hood, which draws from the operating system's cryptographic entropy pool. This is safe for identifier generation. Do not substitute random.randint() or similar non-cryptographic sources.
Rust
The uuid crate supports all major versions:
use uuid::Uuid;
let v4 = Uuid::new_v4();
let v7 = Uuid::now_v7();
println!("{}", v4); // random
println!("{}", v7); // time-sorted
Go
The google/uuid package is the standard choice. It supports v1, v4, v6, and v7:
import "github.com/google/uuid"
v4 := uuid.New() // v4
fmt.Println(v4.String())
v7, _ := uuid.NewV7() // v7 - time-sorted
fmt.Println(v7.String())
Command line
Most Unix systems include uuidgen:
# macOS / Linux
uuidgen
# outputs a v4 UUID
# Or use Python one-liner
python3 -c "import uuid; print(uuid.uuid4())"
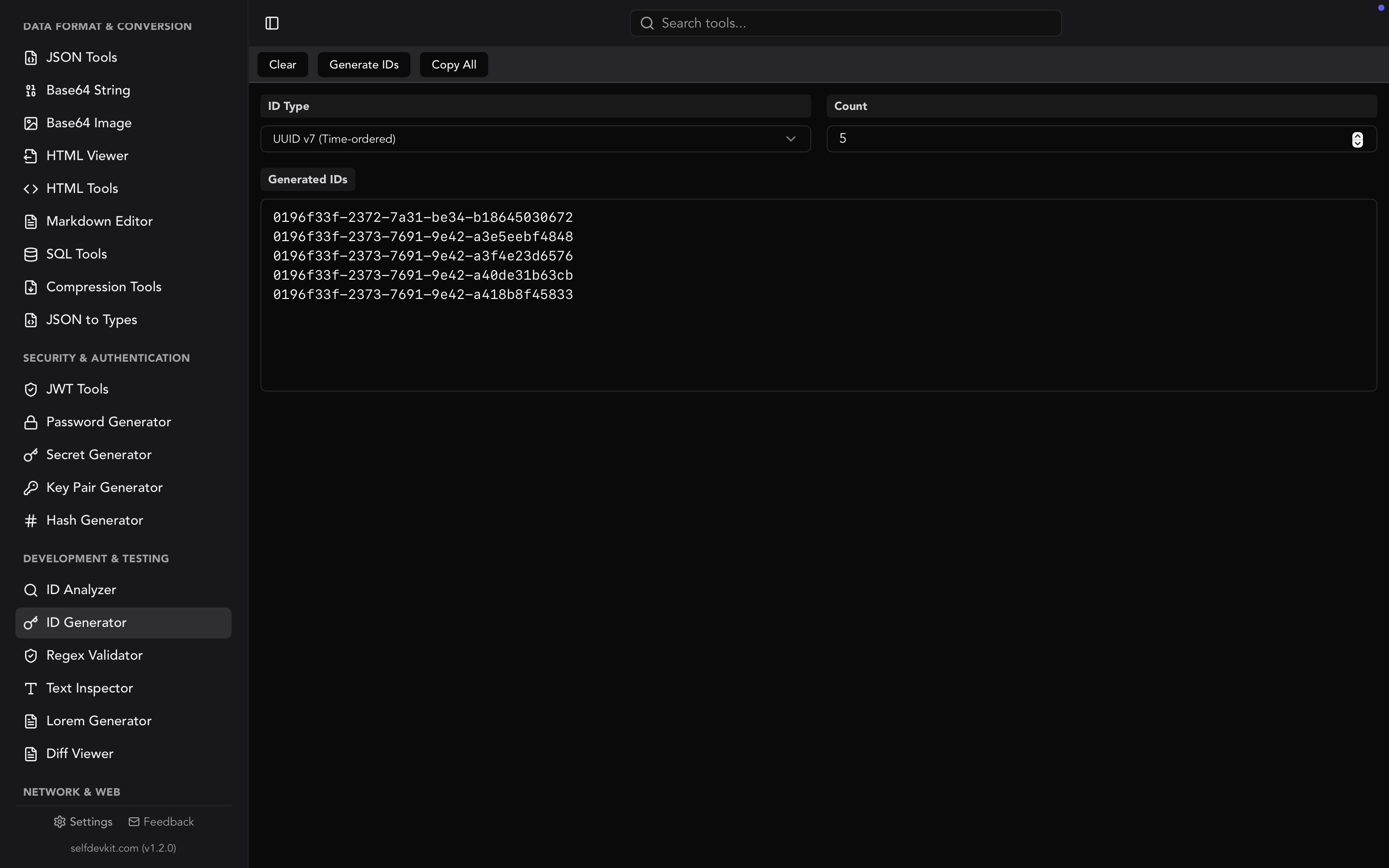
When you need to generate IDs in bulk without writing code, or you want to quickly switch between UUID versions, ULID, NanoID, and KSUID, a dedicated tool is faster than scripting. SelfDevKit's ID Generator lets you pick a format, set a quantity, and generate instantly.
UUID collision probability: the actual math
"Will my UUIDs ever collide?" Short answer: no. Not in practice.
UUID v4 has 122 random bits, giving 5.3 x 10^36 possible values. Using the birthday problem approximation:
P(collision) ≈ n² / (2 × 2^122)
where n is the number of UUIDs generated.
| UUIDs generated | Collision probability |
|---|---|
| 1 million | ~10^-25 |
| 1 billion | ~10^-19 |
| 1 trillion | ~10^-13 |
| 2.71 quintillion | 50% |
To reach a 50% chance of a single collision, you would need to generate 1 billion UUIDs per second for about 86 years. At more realistic rates of thousands per second, the sun will burn out first.
The real risk is not random collision. It is implementation bugs: using Math.random() instead of a cryptographic RNG, seeding with predictable values, or running in a VM that snapshots and restores entropy state. If your UUID library uses crypto.getRandomValues() (browsers), /dev/urandom (Linux), or equivalent, collisions are not a practical concern.
For systems generating millions of IDs per second where even a theoretical risk is unacceptable, KSUID's 128 bits of randomness (versus UUID v4's 122) provides an extra margin of safety.
UUID as a database primary key
Using UUIDs as primary keys is common but comes with tradeoffs that every developer should understand.
The index fragmentation problem
B-tree indexes, used by PostgreSQL, MySQL, and most relational databases, work best with sequential inserts. When you insert a random UUID v4, the database must place it at an arbitrary point in the index tree. This causes:
- Page splits: existing index pages get divided to accommodate the new entry
- Write amplification: more disk I/O per insert
- Cache misses: the working set of index pages grows unpredictably
On a table with millions of rows, random UUID primary keys can cause insert performance to degrade by 2-5x compared to sequential keys. The exact impact depends on your database, storage engine, and working set size.
The v7 solution
UUID v7's timestamp prefix means new IDs are always greater than previous ones (within millisecond precision). Inserts hit the rightmost leaf of the B-tree, just like auto-incrementing integers. You get the distributed generation benefits of UUIDs with the index performance of sequential keys.
CREATE TABLE orders (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(), -- v4, causes fragmentation
-- vs
id UUID PRIMARY KEY, -- use v7 from application layer
created_at TIMESTAMP NOT NULL
);
If your database supports native v7 generation (PostgreSQL 17+ has discussions around this), use it. Otherwise, generate v7 in your application layer and pass it to the database.
Storage considerations
A UUID stored as a string takes 36 bytes. Stored as binary (BINARY(16) in MySQL, UUID type in PostgreSQL), it takes 16 bytes. For tables with millions of rows, the difference in index size is significant. Always use the native UUID column type when available.
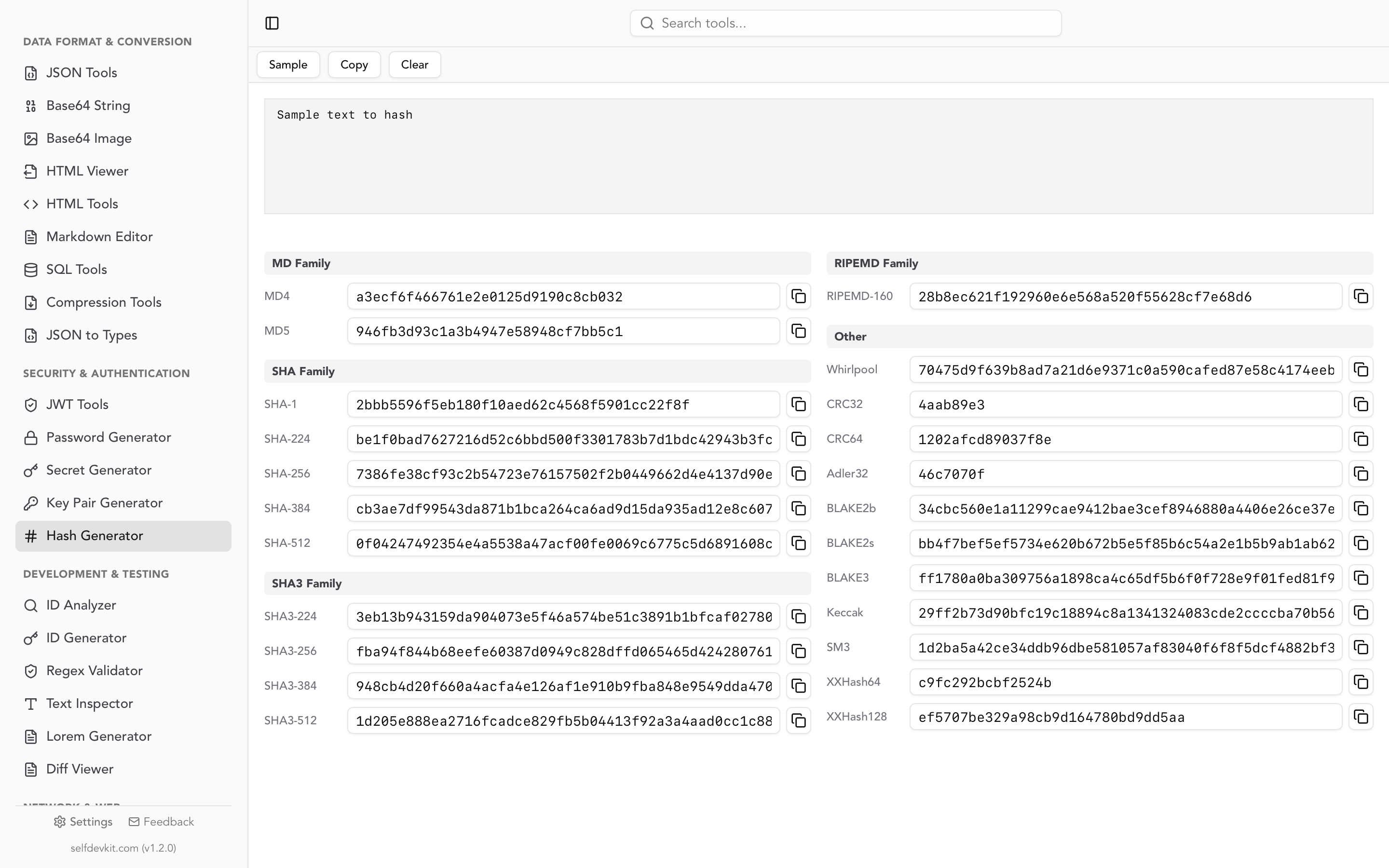
For more on hashing data and verifying integrity, see our hash generator guide. If you are building APIs that return UUIDs in JWT tokens, make sure you understand how token payloads work.
UUID generator: SelfDevKit
SelfDevKit's ID Generator supports all the formats discussed above in a single interface:
- UUID v1, v4, v7 with standard RFC 9562 formatting
- GUID with uppercase/lowercase options
- ULID with Crockford Base32 encoding
- NanoID with configurable length
- KSUID with Base62 encoding
Batch generation
Need 50 UUIDs for a database seed script? Set the quantity and generate them all at once. Copy the entire batch to your clipboard with one click. No loops, no scripts, no pasting one at a time.
Analyze existing IDs
Pair the generator with SelfDevKit's ID Analyzer to decode IDs you encounter. Paste any UUID, ULID, or KSUID and the analyzer extracts the version, timestamp, variant, and other embedded metadata. Useful when debugging distributed systems where you need to know when and where an ID was created.
Offline and private
Every ID is generated locally on your machine using cryptographic randomness from your operating system. Nothing is sent over the network. This matters for development environments that operate behind firewalls or in air-gapped networks where online generators simply are not available.
SelfDevKit includes 50+ developer tools beyond ID generation. JSON formatting, Base64 encoding, regex testing, JWT decoding, and more, all offline, all in one app.
Download SelfDevKit to start generating UUIDs, ULIDs, NanoIDs, and KSUIDs without leaving your desktop.
Frequently asked questions
What is the difference between a UUID and a GUID?
A GUID (Globally Unique Identifier) is Microsoft's name for the same 128-bit identifier format. Functionally, UUIDs and GUIDs are identical. The only difference is convention: GUIDs are typically displayed in uppercase ({550E8400-E29B-41D4-A716-446655440000}), while UUIDs use lowercase. SelfDevKit's ID Generator supports both uppercase and lowercase GUID output.
Is UUID v4 secure enough for authentication tokens?
UUID v4 is unique but not a security token. It uses cryptographic randomness, which makes it unpredictable, but it was designed for identification rather than authentication. For session tokens or API keys, use a dedicated secret generator that produces higher-entropy values with configurable character sets.
Can two UUID v4 values ever be the same?
Mathematically, yes. Practically, no. With 122 random bits, you would need to generate about 2.71 quintillion UUIDs to reach a 50% collision probability. That is 1 billion per second for 86 years. Real-world collision risks come from broken random number generators, not from the math.
Should I use UUID v7 or ULID for database keys?
Both are timestamp-sortable and perform well as primary keys. UUID v7 is the better choice if you want an IETF standard (RFC 9562) and your stack already uses UUID column types. ULID is better if you need compact, URL-safe strings without hyphens. Either one avoids the index fragmentation problem of random UUIDs.